LOS DISTINTOS MOTORES DE BASE DE DATO GRATIS
Y PAGOS..!
Base de datos gratuitos más populares
Sql Server 2008 con Advanced Services:
Microsoft SQL Server 2008 Express with
Advanced Services
es una versión gratuita y fácil de usar de la
plataforma de datos SQL Server Express que incluye una herramienta de
administración gráfica avanzada, así como eficaces características para la
elaboración de informes y la realización de búsquedas avanzadas basadas en
texto. Ofrece herramientas de administración de datos eficaces y confiables,
así como características completas, protección de datos y un rápido
funcionamiento. Es ideal para pequeñas aplicaciones de servidor y almacenes de
datos locales.
Oracle Express Edition:
Oracle Data base 10g Express Edition(Oracle
Data base XE) es una base de datos de entrada de footprint pequeño, creada
sobre la base de código Oracle Database 10g Release 2 que puede desarrollarse,
implementarse y distribuirse sin cargo; es fácil de descargar y fácil de
administrar.
MySql:
MySQLes un sistema de gestión de base de datosrelacional, multihilo y multiusuario con más de seis
millones de instalaciones. MySQL
AB desde enero
de 2008 una subsidiaria de Sun Microsystems y ésta a su vez de Oracle Corporation desde abril
de 2009desarrolla MySQL como software
libre en un esquema de licenciamiento dual.
PostgreSQL:
PostgreSQLes un sistema de gestión de base de datosrelacionalorientada a objetos de software libre, publicado bajo la licenciaBSD.
SQLite:
SQLitees un
sistema de gestión de bases de datos relacional compatible
con ACID, y que está contenida en una
relativamente pequeña (~225 kB[1] ) biblioteca en C. SQLite es un proyecto de dominio público
creado por D. Richard Hipp.
A diferencia de los sistemas de gestión de base de datos
cliente-servidor, el motor de SQLite no es un proceso independiente con el que
el programa principal se comunica. En lugar de eso, la biblioteca SQLite se
enlaza con el programa pasando a ser parte integral del mismo. El programa
utiliza la funcionalidad de SQLite a través de llamadas simples a subrutinas y
funciones. Esto reduce la latencia en el acceso a la base de datos, debido a
que las llamadas a funciones son más eficientes que la comunicación entre
procesos. El conjunto de la base de datos (definiciones, tablas, índices, y los
propios datos), son guardados como un sólo fichero estándar en la máquina host.
Este diseño simple se logra bloqueando todo el fichero de base de datos al
principio de cada transacción.
Firebird:
Firebirdes una base de datos relacional que ofrece
muchas características de SQL ANSI estándar y que funciona en Linux, Windows,
MacOSX y una variedad de plataformas UNIX. Firebird ofrece una concurrencia
excelente, alto rendimiento y un poderoso lenguaje de procedimientos
almacenados y disparadores. Ha estado usándose en producción bajo varios
nombres desde 1981.
ENTRE
OTROS PAGOS Y GRATUITOS ESTAN:

Es una base de datos Open
Source de gran rendimiento, escalable, schema-free
(esquemas de datos tipo JSON). Hay drivers preparados para usar esta base de
datos desde lenguajes como PHP, Python, Perl, Ruby, JavaScript, C++ y muchos
más.

Hypertable es un sistema de
almacenamiento distribuido de datos de alto rendimiento diseñado para soportar
aplicaciones que requieran máximo rendimiento, escalabilidad y eficiencia. Se
ha diseñado y modelado a partir del proyecto BigTable de Google y se enfoca
sobre todo a conjuntos de datos de gran escala.

Como en el caso de MongoDB,
este proyecto está destinado a ofrecer una base de datos orientada a documentos
que se pueden consultar o indexar en modo MapReduce usando JavaScript. CouchDB
ofrece una API JSON RESTful a la que se puede acceder desde cualquier entorno
que soporte peticiones HTTP.

Es un motor de persistencia
completamente transaccional en Java que almacena los datos mediante grafos, y
no mediante tablas. Neo4j ofrece una escalabilidad masiva. Puede manejar grafos
de varios miles de millones de nodos/relaciones/propiedades en una única
máquina, y se puede escalar a lo largo de múltiples máquinas.

Riak es una base de datos
ideal para aplicaciones web y combina:
- Una tienda con un valor clave descentralizado
- Un motor map/reduce flexible
- Una interfaz de consultas HTTP/JSPN amigable.

Se trata de un motor de bases de datos embebidas que proporciona a los desarrolladores persistencia local, rápida y eficiente con una administración nula. Oracle Berkeley DB es una librería que se enlaza directamente en nuestras aplicaciones y permite realizar llamadas simples a funciones en lugar de enviar mensajes a un servidor remoto para mejorar el rendimiento.

EXist-db está
desarrollada a través de la tecnología XML. Almacena datos CML según el modelo
de datos de este estándar, y se caracteriza por un procesado eficiente y basado
en índices de XQuery
MonetDB es un sistema de
bases de datos para aplicaciones de alto rendimiento dirigidas a la minería de
datos, OAP, GIS, búsquedas XML, y recolección de información a partir de
ficheros de texto y multimedia.

4store es un motor de
almacenamiento de bases de datos y de consultas que mantiene datos en formato
RDF. Está escrito en ANSI C99, está diseñado para funcionar en sistemas UNIX y
ofrece una plataforma de alto rendimiento, escalable y estable.

MariaDB es una rama
compatible hacia atrás de MySQL® Database Server. Incluye soporte para la
mayoría de los motores de almacenamiento Open Source, y además para el propio
motor de almacenamiento Maria.

Cassandra es probablemente uno
de los proyectos NO SQL más concoidos del mercado. Se trata de una base de
datos distribuida de segunda generación con alta escalabilidad que está siendo
usada por gigantes como Facebook (que es quien la ha desarrollado), Digg,
Twitter, Cisco y más empresas. El objetivo es ofrecer un entorno consistente,
tolerante a fallos y de alta disponibilidad a la hora de almacenar datos.

Memcachedes un almacen del
tipo in-memory key-valuepara pequeñas cadenas de datos arbitrarios (textos,
objetos) de resultados de llamadas a base de datos, llamadas a API, o
renderizado de páginas. Está orientado a acelerar aplicaciones web dinámicas al
aliviar la carga de la base de datos.

HBase es u almacén distribuido
del tipo column-orientedque puede ser también denominado como la base de datos
Hadoop. El proyecto está dirigido a ofrecer tablas enormes de “miles de
millones de filas, y millones de columnas”. Dispone de un Gateway RESTful que
soporta XML, Protobug y opciones de codificación binaria de datos.

Redis es una base de datos
avanzada del tipo fast key-value queestá escrita en C y quese puede usar
como memcached, por delante de una base de datos tradicional, o bien por sí
sola de forma independiente. Tiene soporte para varios lenguajes de
programación y se utiliza en proyectos muy populares como GitHub o Engine Yard.
También hay un cliente PHP llamado Rediska que permite gestionar bases de datos Redis.
OTRAS ALTERNATIVAS
- OpenQM (base de datos multivalor)
- ScarletDME (base de datos multivalor)
- SmallSQL (Motor de bases de datos Java Desktop SQL)
- LucidDB
- HyperGraphDB (base de datos de grafos)
- InfoGrid(base de datos de grafos)
- Apache Derby
- hamsterdb
- H2 Database
- EyeDB
- txtSQL
- db4o
- Tokyo
Cabinet
- Project Voldemort
-
MODELO RELACIONAL:Modelo de datos relacional

-
Este modelo es el más utilizado actualmente ya que utiliza tablas bidimensionales para la representación lógica de los datos y sus relaciones.
Algunas de sus principales características son: - Puede ser entendido y usado por cualquier usuario.
- Permite ampliar el esquema conceptual sin modificar las aplicaciones de gestión.
- Los usuarios no necesitan saber dónde se encuentran los datos físicamente.
El elemento principal de este modelo es la relación que se representa mediante una tabla.
Modelo
de datos jerárquico

Las estructuras jerárquicas fueron usadas extensamente en los primeros sistemas de gestión de datos de unidad central, como el Sistema de Dirección de Información (IMS) por la IBM, y ahora describen la estructura de documentos XML. Esta estructura permite un 1: N en una relación entre dos tipos de datos.
Esta estructura es muy eficiente para describir muchas relaciones en el verdadero real; recetas, índice, ordenamiento de párrafos/versos, alguno anidó y clasificó la información. Sin embargo, la estructura jerárquica es ineficaz para ciertas operaciones de base de datos cuando un camino lleno (a diferencia del eslabón ascendente y el campo de clase) también no es incluido para cada registro.
Modelo de datos en red
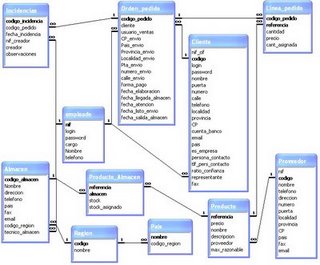
En este modelo las entidades se representan como nodos y sus relaciones son las líneas que los unen. En esta estructura cualquier componente puede relacionarse con cualquier otro.
A diferencia del modelo jerárquico, en este modelo, un hijo puede tener varios padres.
Los conceptos básicos en el modelo en red son:
- El tipo de registro, que representa un nodo.
- Elemento, que es un campo de datos.
- Agregado de datos, que define un conjunto de datos con nombre.
Este modelo de datos permite
representar relaciones N: M
LA DIFERENCIA ENTRE ELLOS:
Bueno la diferencia entre ellos es
casi notoria pues si hablamos del modelo Relacional este Permite ampliar el
esquema conceptual pero no modificar las
aplicaciones de gestión.
Además el modelo de red es una variación sobre el modelo
jerárquico, al grado que es construido sobre el concepto de múltiples ramas
(estructuras de nivel inferior) emanando de uno o varios nodos (estructuras de
nivel alto), mientras el modelo se diferencia del modelo jerárquico en esto las
ramas pueden estar unidas a múltiples nodos. El modelo de red es capaz de
representar la redundancia en datos de una manera más eficiente que en el
modelo jerárquico.
COMO CREAR UNA BASE DE DATO SQL SERVER:
Introducción:
En este artículo te explico los pasos que
debes dar para crear una base de datos de SQL Server 2005 con el Management
Studio. Además de ejecutar ciertos comandos "scripts" para crear una
tabla y asignarle algunos datos.
Estos pasos son para crear la base de datos Pruebas
Guille y la tabla Clientes. Además de añadirle algunos datos.
Para crear la tabla y añadir los datos, usarás
dos ficheros con el código de T-SQL (Transact SQL) necesario para ejecutarlo
desde una ventana de código del Management Studio.
Aquí te lo explico para la versión Express,
pero es válido también para la versión "normal" del Management Studio
de SQL Server 2005.
Los pasos que debes dar son:
1- Abre el Management Studio y selecciona la instancia en la que quieres trabajar, en la figura 1 es la instancia de SQLEXPRESS.
Figura 1. Conectar a un servidor de bases de datos con el Management Studio
2- Con el botón derecho (o el botón secundario), pulsa en Bases de datos y del menú selecciona Nueva base de datos, tal como te muestro en la figura 2.

Figura 2. Crear una nueva base de datos
3- Eso hará que te muestre una ventana como la de la figura 3.
A la base de datos, le vas a dar el nombre PruebasGuille, así que escribe ese nombre en la caja de textos correspondiente y después pulsa en el botón Aceptar.

Figura 3. Cuadro de diálogo de Nueva base de datos
4- Ahora vamos a escribir el código para crear la tabla Clientes.
¡No te asustes! que no vas a escribir nada, ya que ese código lo puedes obtener de un fichero que ya tengas. En este caso, el que se acompaña con el código fuente del artículo de Auto completar usando una base de datos (o si lo prefieres: Buscar en una base de datos mientras se escribe).
5- En la base de datos que hemos creado, pulsa con el botón derecho del ratón para que te muestre el menú contextual, del que seleccionarás Nueva consulta, tal como puedes ver en la figura 4.

Figura 4. Crear una nueva consulta en Management Studio
6- Eso hará que se muestre una ventana en el panel de la derecha (junto a la ficha Resumen).
7- Abre el fichero Crear la tabla de Clientes de PruebasGuille.sql con un editor de textos y selecciona todo el texto, lo copias y lo pegas en esa ventana.
7.1- También puedes abrir el fichero, en ese caso, te preguntará en que instancia, etc. lo quieres ejecutar (la misma pregunta que te hace en la figura 1).
8- Una vez que tienes el texto pegado en la ventana de consultas, pulsa en el botón Ejecutar (ver la figura 5), o bien pulsa la tecla F5.

Figura 5. Ejecutar la consulta
9- Esto creará la tabla Clientes con los datos que se indican en el fichero que son los mismos que puedes ver en la figura 5.
10- Si expandes la base de datos y pulsas en Tablas, verás que ya está la tabla creada, tal como te muestro en la figura 6.

Figura 6. La tabla de Clientes ya está creada
11- Ahora vamos a añadir unos cuantos datos.
12- Abre el fichero Agregar datos de ejemplo a la tabla Clientes de PruebasGuille.sql y copia el contenido y lo pegas en la misma ventana de consultas que tenemos.
12.1- Recuerda que también puedes abrir el fichero.
13- Una vez que tienes el código de inserción de los datos de ejemplo, pulsa nuevamente en Ejecutar y se añadirán esos datos.
14- Y si abres la tabla de Clientes para que te muestre lo que tiene, verás que será algo como lo que te muestro en la figura 7.

Figura 7. Los datos que acabamos de añadir a la tabla de Clientes
15- Y una vez que tienes estos datos en la base de datos, ya puedes usar el código, por ejemplo, el del artículo de buscar mientras se escribe, tal como ves en la figura 8.

Figura 8. Ya podemos acceder a los datos
Como te puedes imaginar, en la ventana de consulta puedes escribir el código de SQL que quieras, y así de camino pruebas cosas antes de usarla en tu código.
DROP TABLE
La sentencia DROP TABLE
sirve para eliminar una tabla. No
se puede eliminar una tabla si está abierta, tampoco la podemos
eliminar si el borrado infringe las reglas de integridad referencial (si
interviene como tabla padre en una relación y tiene registros relacionados).
La sintaxis es la
siguiente:
|
Ejemplo:
DROP TABLE tab1
Elimina de la base de datos la tabla tab1.
|
La sentencia CREATE INDEX
sirve para crear un índice
sobre una o varias columnas de una tabla. Si quieres repasar conceptos
básicos sobre índices haz clic aquí
La sintaxis es la
siguiente:
|
 |
nbindi: nombre
del índice que estamos definiendo. En
una tabla no pueden haber dos índices con el mismo nombre
de lo contrario da error.
nbtabla: nombre
de la tabla donde definimos el índice.
A continuación entre paréntesis se indica la composición
del índice (las columnas que lo forman).
nbcol: nombre
de la columna que indexamos. Después del nombre de la
columna podemos indicar cómo queremos que se ordenen las filas
según el índice mediante las cláusulas ASC/DESC.
ASC: la cláusula
ASC es la que se asume por
defecto e indica que el orden
elegido para el índice es ascendente (en
orden alfabético si la columna es de tipo texto, de menor a mayor
si es de tipo numérico, en orden cronológico si es de tipo
fecha).
DESC: indica orden
descendente, es decir el orden inverso al ascendente.
Podemos formar un índice basado
en varias columnas, en este caso después de indicar
la primera columna con su orden, se escribe una coma y la segunda columna
también con su orden, así sucesivamente hasta indicar todas
las columnas que forman el índice.
Opcionalmente se pueden indicar las cláusulas:
WITH PRIMARY indica
que el índice define la clave principal
de la tabla, si la tabla ya tiene una clave principal, la sentencia
CREATE INDEX dará error.
WITH DISALLOW NULL
indica que no permite valores nulos
en las columnas que forman el índice.
WITH IGNORE NULL
indica que las filas que tengan
valores nulos en las columnas que forman el índice se
ignoran, no aparecen cuando recuperamos las filas de la tabla
utilizando ese índice.
|
Ejemplo:
CREATE UNIQUE INDEX ind1 ON
clientes (provincia, poblacion ASC, fecha_nacimiento DESC)
Crea un índice llamado ind1 sobre la tabla
clientes formado por las columnas provincia, población
y fecha_nacimiento. Este índice permite tener ordenadas las
filas de la tabla clientes de forma que aparezcan los clientes
ordenados por provincia, dentro de la misma provincia por población
y dentro de la misma población por edad y del más joven
al más mayor.
Al añadir la cláusula UNIQUE
el índice no permitirá duplicados por lo que no podría
tener dos clientes con la misma fecha de nacimiento en la misma población
y misma provincia, para evitar el poblema sería mejor utilizar:
CREATE INDEX ind1 ON clientes
(provincia, poblacion ASC, fecha_nacimiento DESC)
|
La sentencia DROP INDEX
sirve para eliminar un índice
de una tabla. Se elimina el índice pero no las columnas que lo
forman.
La sintaxis es la
siguiente:
|
Ejemplo:
DROP INDEX ind1 ON clientes
Elimina el índice que habíamos creado
en el ejemplo anterior.
Sintaxis de CREATE TRIGGER
CREATE TRIGGER nombre_disp momento_disp evento_disp
ON nombre_tabla FOR EACH ROW sentencia_disp
Un disparador es un objeto con nombre en una base de datos que se
asocia con una tabla, y se activa cuando ocurre un evento en
particular para esa tabla.
El disparador queda asociado a la tabla
nombre_tabla. Esta debe ser una tabla
permanente, no puede ser una tabla TEMPORARY ni
una vista.
Momento_disp es el momento en que el
disparador entra en acción. Puede ser BEFORE
(antes) o AFTER (despues), para indicar que el
disparador se ejecute antes o después que la sentencia que lo
activa.
evento_disp indica la clase de
sentencia que activa al disparador. Puede ser
INSERT, UPDATE, o
DELETE. Por ejemplo, un disparador
BEFORE para sentencias
INSERT podría utilizarse para validar los
valores a insertar.
No puede haber dos disparadores en una misma tabla que correspondan al mismo momento y sentencia. Por ejemplo, no se pueden tener dos disparadores
BEFORE UPDATE.
Pero sí es posible tener los disparadores BEFORE
UPDATE y BEFORE INSERT o
BEFORE UPDATE y AFTER
UPDATE.
sentencia_disp es la sentencia que se
ejecuta cuando se activa el disparador. Si se desean ejecutar
múltiples sentencias, deben colocarse entre BEGIN ...
END, el constructor de sentencias compuestas. Esto
además posibilita emplear las mismas sentencias permitidas en
rutinas almacenadas.Note: Antes de MySQL 5.0.10, los disparadores no podían contener referencias directas a tablas por su nombre. A partir de MySQL 5.0.10, se pueden escribir disparadores como el llamado
testref, que se
muestra en este ejemplo:
CREATE TABLE test1(a1 INT);
CREATE TABLE test2(a2 INT);
CREATE TABLE test3(a3 INT NOT NULL AUTO_INCREMENT PRIMARY KEY);
CREATE TABLE test4(
a4 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
b4 INT DEFAULT 0
);
DELIMITER |
CREATE TRIGGER testref BEFORE INSERT ON test1
FOR EACH ROW BEGIN
INSERT INTO test2 SET a2 = NEW.a1;
DELETE FROM test3 WHERE a3 = NEW.a1;
UPDATE test4 SET b4 = b4 + 1 WHERE a4 = NEW.a1;
END
|
DELIMITER ;
INSERT INTO test3 (a3) VALUES
(NULL), (NULL), (NULL), (NULL), (NULL),
(NULL), (NULL), (NULL), (NULL), (NULL);
INSERT INTO test4 (a4) VALUES
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0);
Si en la tabla test1 se insertan los siguientes
valores:
mysql> INSERT INTO test1 VALUES
-> (1), (3), (1), (7), (1), (8), (4), (4);
Query OK, 8 rows affected (0.01 sec)
Records: 8 Duplicates: 0 Warnings: 0
Entonces los datos en las 4 tablas quedarán así:
mysql> SELECT * FROM test1;
+------+
| a1 |
+------+
| 1 |
| 3 |
| 1 |
| 7 |
| 1 |
| 8 |
| 4 |
| 4 |
+------+
8 rows in set (0.00 sec)
mysql> SELECT * FROM test2;
+------+
| a2 |
+------+
| 1 |
| 3 |
| 1 |
| 7 |
| 1 |
| 8 |
| 4 |
| 4 |
+------+
8 rows in set (0.00 sec)
mysql> SELECT * FROM test3;
+----+
| a3 |
+----+
| 2 |
| 5 |
| 6 |
| 9 |
| 10 |
+----+
5 rows in set (0.00 sec)
mysql> SELECT * FROM test4;
+----+------+
| a4 | b4 |
+----+------+
| 1 | 3 |
| 2 | 0 |
| 3 | 1 |
| 4 | 2 |
| 5 | 0 |
| 6 | 0 |
| 7 | 1 |
| 8 | 1 |
| 9 | 0 |
| 10 | 0 |
+----+------+
10 rows in set (0.00 sec)
Las columnas de la tabla asociada con el disparador pueden referenciarse empleando los alias
OLD y
NEW.
OLD.nombre_col hace
referencia a una columna de una fila existente, antes de ser
actualizada o borrada.
NEW.nombre_col hace
referencia a una columna en una nueva fila a punto de ser
insertada, o en una fila existente luego de que fue actualizada.
El uso de
SET NEW.nombre_col =
valor necesita que se tenga
el privilegio UPDATE sobre la columna. El uso
de SET nombre_var =
NEW.nombre_col necesita el
privilegio SELECT sobre la columna.
Nota: Actualmente, los disparadores no son activados por acciones llevadas a cabo en cascada por las restricciones de claves extranjeras. Esta limitación se subsanará tan pronto como sea posible.
La sentencia
CREATE TRIGGER necesita el
privilegio SUPER. Esto se agregó en MySQL
5.0.2.